Anatomía de un proyecto de software
Gestión del proyecto con SCRUM
Cuando se suma una persona al equipo lo capacitamos en Scrum, el flujo de tareas de JIRA, la carga de horas y de ausencias. La persona recibe una invitación a JIRA y lo sumamos a un equipo Scrum, con un rol determinado.
¿Cómo trabajamos en Andreani?
Cuando iniciamos un proyecto realizamos una Incepción Ágil, que es un conjunto de dinámicas orientadas a enfocar a todas las personas involucradas en un proyecto hacia un mismo objetivo, reduciendo incertidumbres, explicitando riesgos y poniendo en común las expectativas de todos. Se construye una visión compartida y comprendida de idéntica forma por los comprometidos, involucrados e interesados, de manera que se eviten los sesgos personales.
A su vez creamos el proyecto y el tablero en JIRA, que es la herramienta que utilizamos en todos los proyectos de software.
El corazón de Scrum es el Sprint, es un bloque de tiempo (time-box) de un mes o menos durante el cual se crea un incremento de producto “Terminado” utilizable y potencialmente desplegable. Cada nuevo Sprint comienza inmediatamente después de la finalización del Sprint anterior.
Nosotros trabajamos con sprints de 2 semanas y en proyectos puntuales que necesitamos más feedback lo acortamos a 1 semana. Los Sprints contienen y consisten en la Planificación del Sprint (Sprint Planning), los Scrums Diarios (Daily Scrums), el trabajo de desarrollo, la Revisión del Sprint (Sprint Review), y la Retrospectiva del Sprint (Sprint Retrospective).
Al finalizar un sprint nosotros realizamos la revisión del sprint, “el cierre del sprint”, hacemos una retrospectiva con el formato (stop, start, continue) y realizamos la planificación del nuevo sprint.
En la reunión de revisión del sprint, recorremos las tareas en JIRA y a las tareas que no están completadas verificamos que tengan registrado el tiempo restante para completar las mismas. Durante esta reunión el equipo puede mostrar software funcionando y el Product Owner brindar feedback. El Product Owner decide si se cumplió con el objetivo del sprint. Utilizamos un Excel para el cierre del sprint donde obtenemos las incidencias desde JIRA y visualizamos las tareas completadas y si hay tareas pendientes, visualizamos las horas pendientes y las completadas respecto a las planificadas para analizar la velocidad que puede desarrollar el equipo. Registramos si cumplimos el objetivo del sprint y, si no, ingresamos un comentario con el motivo del rechazo.
Para medir la velocidad del equipo nos estamos basando en horas en vez de story points. En la planificación utilizamos el Excel para calcular las horas que cada integrante del equipo puede comprometer en el próximo sprint. Tenemos en cuenta su disponibilidad horaria, si va a tener días de ausencia durante el sprint y el porcentaje de dedicación al proyecto. También reservamos un porcentaje de dedicación a otras tareas que no son exclusivamente de desarrollo, por ejemplo resolución de incidentes de producción. A medida que el equipo selecciona las historias de usuario a realizar en el sprint, se crean las subtareas correspondientes en JIRA, donde se asignan cada subtarea a un miembro del equipo y se la estima en horas. Con el Excel obtenemos las incidencias creadas en JIRA y vemos a que personas le quedan horas disponibles y analizamos si estamos tomando tareas que superen la velocidad del equipo, en cuyo caso tenemos que renegociar cuáles son las tareas que se realizarán en el sprint. Las tareas deben estar alineadas al objetivo del sprint.
Actualizamos nuestras bases de datos con los datos del cierre y la planificación y disponibilizamos la información del Excel en el sitio de proyectos de Sharepoint, donde podemos consultar:
- En el inicio, el calendario de los próximos eventos.
- En históricos sprints, los sprints realizados con sus objetivos y resultados.
- En cada proyecto, la planificación del sprint actual y el cierre del sprint anterior con el detalle de cada tarea y del resultado del sprint y de la velocidad del equipo.
- En documentos, podemos agregar documentación funcional y técnica para cada proyecto. Por ejemplo para el proyecto de Indicadores estamos construyendo una wiki con la construcción de cada indicador relevante para Andreani.
Con respecto a los Scrum diarios, el equipo de desarrollo se reúne para sincronizar las actividades del equipo y hacer una revisión del progreso. Cada integrante del equipo menciona que hizo, que hará y si tiene algún impedimento. Estamos implementando que cada equipo tenga su propia pizarra y por medio de post-it visualizar el avance de las tareas en el sprint. Con respecto a las retrospectivas, realizamos retros para reflexionar sobre cómo trabajamos y explorar oportunidades de mejora en los procesos, herramientas y sobre cómo se siente el equipo, y decidir como experimentar con lo aprendido.
¿Cómo se compone un equipo Scrum?
Un equipo Scrum tiene un Product Owner, un Scrum Master y el Equipo de Desarrollo. El equipo es auto-organizado, multifuncional, donde todos somos responsable de todo y no existen jerarquías.
El Product Owner es el responsable de maximizar el valor del producto, el software que estamos construyendo. Es el único responsable del product backlog y refina los requerimientos para agregar detalle, estimar y priorizar. Para esta tarea cuenta con el Equipo de Desarrollo. Y tiene la autoridad para aprobar o rechazar un sprint como también para cancelarlo.
El Scrum Master asegura que Scrum se entienda y se adopte, es un líder al servicio del equipo Scrum. Facilita y se encarga de remover impedimentos y motiva cambios que incrementen la productividad del equipo.
El equipo de Desarrollo se compone de 3 a 9 miembros y son auto-organizados, responsables del sprint backlog y de medir su velocidad. Son empoderados, toman sus propias decisiones, sin jerarquías.
En nuestro sitio Agile de Sharepoint, podemos consultar contenido, notas y videos relacionados con las prácticas ágiles en nuestros procesos de desarrollo:
- En Aprendizaje: contiene artículos, bibliografía, cursos, exámenes y videos.
- En Capacitaciones: capacitaciones de Scrum.
- En Herramientas: instructivos de JIRA, PowerApps, presentaciones.
- En Templates: Excel para planificar sprints.
También en nuestro sitio Indicadores en Sharepoint podemos consultar nuestros indicadores internos, con detalle de cada equipo y e cada integrante y para Clientes.
Repositorios y gestión de código fuente
Todo el código fuente de los desarrollos internos de GLA está en GitHub. Ahí están los repositorios de cada uno de los proyectos. Para poder comenzar a colaborar en ellos se precisa un usuario de github , haber sido invitado a participar de la organización y pertenecer a uno de los equipos ahí definidos que son los que dan autorización para trabajar en un repositorio u otro.
Readme.md
Todos los proyectos en GitHub tienen un Readme.md que debe basarse en la siguiente plantilla. Qué apartados de la planilla hay que llenar y cuáles no queda a criterio del que confecciona. Este activo, como cualquier otro, queda sujeto a revisión de pares.
Gitflow.
No voy a ser escrupuloso en la descripción de cómo funciona un proceso de desarrollo por falta de tiempo y por no ser redundante. Internet está repleto de información al respecto. De todas formas, vamos a dar un paseo rápido y simplificado de cómo es en Andreani. Esencialmente GLA se maneja mediante el flujo de desarrollo definido por GitFlow.
En resumen (ver la figura), la rama de desarrollo principal se llama develop (naranja) y la de producción master (verde). Todos los desarrolladores aportan a develop mediante features (celeste) y pull request (PR) que hacen hacia develop. De vez en cuando se planifica un release (amarillo) a partir de un punto de develop y luego al cerrar ese release todos los cambios se combinan (merge) con master. SI hay que hacer una corrección de emergencia en producción se abre un hotfix (violeta) y al cerrarlo se mergea con master y develop.
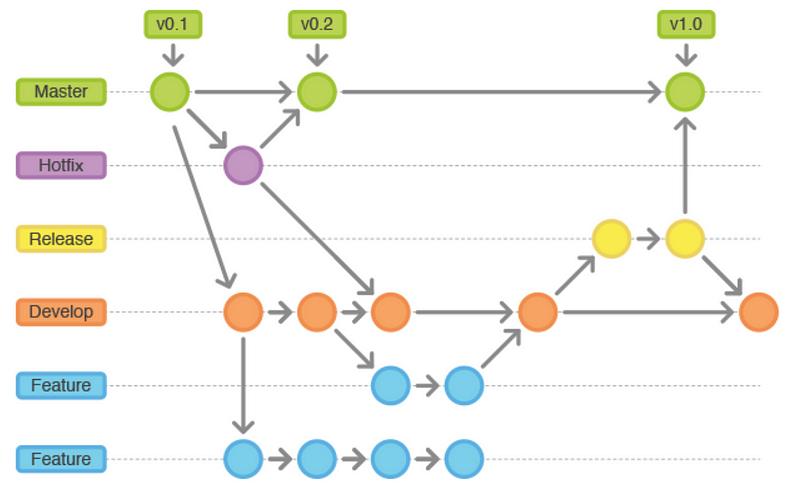
Convenientemente todas estas ramas están relacionadas con el sistema de integración continua (CI) que realiza los despliegues automáticamente en el ambiente que corresponda. Cada release tiene un número de versión establecido en base a las políticas descriptas en SemVer.
Ver también
Ambientes y despliegues en el desarrollo in-house
Versionado de artefactos de software en GLA
Manual del programador
Lo que sigue a continuación es una descripción lo más exhaustiva posible sobre el estilo en que se debe programar en GLA. Los ejemplos están todos en C# pero en la mayoría de los casos esto debería ser anecdótico. Hay que notar que hay algo de arbitrario en toda confección de un manual de estilos; el objetivo es más que nada establecer una práctica y un criterio común para poder lograr integridad y facilitar la lectura y la adopción.
Convenciones de nombrado y otras prácticas
Respetamos y seguimos las siguientes convenciones y prácticas:
- PascalCase al nombrar clases, métodos y propiedades.
public class GestorDeEventos { ... } public void Execute(object param) { ... } public string ConnectionInfo { get; set; } - camelCase al nombrar variables locales a un método.
MessageHandlerAdaptor handler; - camelCase con prefijo underscrore (_) al nombrar variables privadas de clase. Usar readonly cada vez que sea posible.
private static readonly MqConfig _mqCfg; private readonly EndPoints _endPointsCfg; - Las interfaces deben empezar con I. Ej:
public interface IServicios { ... } - No usar nombres de variables de una sola letra. Una excepción son lo índices en los loops:
for ( int i = 0; i < count; i++ ) { ... } - Los namespaces deben tener la siguiente forma:
namespace Andreani.{NombreDelProyecto}.{ModuloSuperior}.{ModuloInferior} { .... } - El uso de las llaves es según el estilo Allman, cada llave { } va en una línea aparte.
for (int j = 1; j \<= n; j++) { /// si son iguales en posiciones equidistantes el peso es 0 /// de lo contrario el peso suma a uno. costo = (s[i - 1] == t[j - 1]) ? 0 : 1; d[i, j] = System.Math.Min(System.Math.Min(d[i - 1, j] + 1, //Eliminacion di, j - 1] + 1), //Insercion d[i - 1, j - 1] + costo); //Sustitucion }Salvo que sea una sola línea y entonces puede ir sin llaves:
if (!normalizador.VerificarSiPudoNormalizar(localidadNormalizada)) return HttpStatusCode.NoContent; - Siempre especificar la visibilidad, aunque sea el default.
private MaquinaDeEstadosDeEnvio _maquinaDeEstados; - Evitar tener dos líneas en blanco seguidas.
- Solo usar var cuando es obvio el tipo de dato a que se refiere:
var count = 1; //OK - En las clases definir las variables miembro arriba de todo.
- Preferir string a String e int o long a Int32 o a Int64.
- Evitar el uso de la palabra clave this.
- El nombre de los métodos deben expresar una acción y los de las propiedades un atributo:
public void EntregarPorMostrador(Envio unEnvioEntregable) { ... } //OK public void EstadoDeEnvio Estado { get; } //OK public void RequisitosDeEntrega(Envio unEnvioEntregable) { ... } //ERROR - Preferimos que las propiedades y los métodos que devuelven
boolse escriban como contestando una pregunta de respuesta verdadero o falso:public bool EstaActivo { get; } //OK public bool Activo { get; } // ERROR - Intentar que los argumentos de los métodos expresen bien qué clase de rol cumplen en la llamada:
public void ActualizarDestino(Geo unDestinoNuevo) { .. } //OK public void ActualizarDestino(Geo geo) { ... } //ERROR public void Agregar(Envio contenido) { ... } //OK public void Agregar(Envio envio) { ... } //ERROR - Verificar si es más expresivo que los métodos que devuelvan colecciones empiecen con la palabra Listar. Y si son propiedades, deberían estar en plural.
public IList<Sucursal> ListarSucursalesDeUnaRegion(string elNombreDeUnaRegion) {...} public ISet<double> Tarifas { get; set; } = new HashSet<double>(); - No subir a GitHub bloques de código comentado de esta forma:
//public override int GetHashCode() //{ // return GeneradorDeHashCode.GetHashCodeFNV(Tipo, Modulo); //} // //public override bool Equals(object obj) //{ // var otro = obj as IdClass; // return otro != null && otro.Tipo == Tipo && otro.Modulo == Modulo; //}Si vas a comentar toda una parte, borrála directamente o especificá claramente por qué.
- Las excepciones personalizadas deben nombrarse terminando con la palabra Exception:
public class NoEsUnContenedorException : ArgumentException { ... }Comentarios
Los metodos que precisen comentarios se comentan utilizando el estándar de VisualStudio:
// <summary>
/// Actualiza el estado de un contenedorDistribuible a partir de un evento
/// </summary>
/// <param name="evento"><param>
/// <returns>true si se produjo un cambio de estado\<returns>
protected virtual bool ActualizarEstado(EventosDeContenedoresNoDistribuibles evento)
Evitar comentarios excesivos. Esforzarse por escribir el código con una claridad tal de que estos no sean necesarios. Si creés que del código no se puede inferir lo que hace con una lectura rápida, entonces ahí es recomendable una aclaración.
No alcanza con que la computadora entienda el programa, otra persona también tiene que entenderlo.
En una jerarquía de clases, siempre comentar el método más abstracto. Recordar que nuestro diseño también debe respetar el principio de sustitución de Liskov. Las sucesivas sobrecargas en las subclases deben utilizar <inheritdoc />
///<summary>
/// Si el contenedor esta abierto
///</summary>
bool EstaAbierto { get; }
/// <inheritdoc />
public virtual bool EstaAbierto => InformacionDeEstado.Estado == CASADefinesV2.EntityNumberState.Open;
Excepciones
Nosotros hacemos un uso extensivo de las excepciones para gestionar el flujo de ejecución en presencia de errores. Por lo tanto, seguir las siguientes recomendaciones:
- Arrojar excepciones cuando el método se encuentra con una situación anormal y no puede seguir.
Nota Se sabe que es difícil de discernir si una situación es anormal y que hay veces que lo más indicado es devolver un valor inválido o un código de error. Ante la duda, arrojá un excepción. Supongamos este ejemplo:
Stream str = ... if (stream.Read()>0) { .... } Bien se podría haber arrojado una excepción en el Read() si es que se llegó al final del stream, pero como Read() devuelve la cantidad de bytes leídos y que el stream finalice no debería ser una situación *anormal* (todos los archivos terminan), el diseñador prefirió devolver -1 en este caso.
- Nunca arrojar
System.Exception. - Intentar en lo posible atrapar la excepción mas concreta. Por ejemplo,
ArgumentNullExceptionaArgumentException. Verificar el código que se llama para ver qué excepciones puede arrojar y gestionarlas. - Nunca silenciar una excepción. Hay casos especiales en que puede ser válido, pero en la mayoría de los casos es una mala práctica:
try { //... } catch (Exception e) { } - En presencia de excepciones, el objeto que la arroja debe quedar en un estado estable, es decir, debe mantener sus invariantes. No es válido que un objeto quede con valores ilegales luego de arrojar una excepción. Por lo tanto, cuando la arrojes, asegurate que el objeto que se intentó modificar quede con los valores que tenía antes de que alguien invoque al método que causó la excepción.
- Si existen excepciones del framework que expresan la condición, usar esas y no personalizadas.
- Si vas a usar una excepción personalizada la misma debería tener funcionalidad que permita saber mejor qué fue lo que pasó, o que describa información de contexto.
public class ObjetoNoEncontradoException : ArgumentException { public ObjetoNoEncontradoException(object id, Type @class, string msg = null, Exception inner = null) : base(msg, inner) { Id = id; Clase = @class; } public object Id { get; private set; } public Type Clase { get; private set; } }
Además, siempre poner el argumento para pasarle a la superclase el inner exception y el mensaje.
- Usar
nameof(paramName)y no"paramName"al arrojar una excepción que tome un nombre de parámetro como argumento.throw new ArgumentNullException(nameof(numeroDeEnvio)); //OK throw new ArgumentNullException("numeroDeEnvio"); //ERROR - Es importante también documentar qué excepciones arroja un método:
/// <summary> /// <para>str</para> debe venir en la forma en que lo devuelve Rango.ToString() /// </summary> /// <param name="str">El rango a parsear, ej: 1 - 10</param> /// <returns></returns> /// <exception cref="NotSupportedException"></exception> /// <exception cref="ArgumentOutOfRangeException"></exception> /// <exception cref="NullReferenceException"></exception> public static Rango<T> Parse(string str) { ... } - Si hay que relanzar la excepción en un catch, preferir la cláusula
throwsolitaria. Esto preserva el callstack. Ejemplo:try { //.... } catch(Exception e) { // .... throw e; //ERROR throw; //OK }Cross-Platform
El software que hacemos debe correr también en Linux. Por lo tanto hay que tener en cuenta lo siguiente:
-
Usar
Enviroment.NewLineen lugar de harcodear los finales de línea. Windows usa\r\ny OSX/Linux usan\n. - Usar
Path.Combine()oPath.DirectorySeparatorCharpara separar directorios. Si no es posible, usar/(barra hacia adelante) como enC:/IntegraCoreServices/MiApp/Logs
Consideraciones de diseño.
Pensar bien los nombres de las clases, propiedades y métodos. Encontrar el nombre que mejor represente el concepto que se quiere modelar. Preguntarle a algún compañero/a opiniones al respecto. Recordar que si no sabés que nombre ponerle a una clase es porque seguramente no sabés qué es lo que querés representar realmente. Lo mismo para los métodos y propiedades.
El modelo de dominio siempre hay que programarlo en el idioma del negocio, esto es, castellano. Los usuarios no dicen shipment sino envio; y hay cuestiones culturales que son muy difíciles de traducir. Vos estás leyendo esto porque sos un programador y no un sociólogo. Nosotros podemos ayudarle al negocio a pensar pero no inventamos el léxico, lo encontramos con ellos si hace falta. Además, nadie domina realmente el inglés (o son pocos los casos) como para tener la destreza de encontrar la palabra adecuada en todos los casos: ya nos cuesta demasiado en español.
La forma correcta de programar es adoptar una posición defensiva. Nunca confíes en que el que llama a tu código va a pasar los argumentos de forma correcta ni que el código que vas a llamar va a resultar sin excepciones. Proteger siempre el código chequeando el valor correcto de los parámetros y si no validan arrojar la excepción adecuada. Si vas a llamar a un método que no es tuyo, intentar averiguar qué excepciones puede arrojar y estar preparado para gestionarlas. Librerías como Polly pueden ayudar mucho cuando tu código tiene que llamar a otro menos confiable.
No diseñes para adelante. Nunca se sabe lo que el PO puede pedir. Es preferible siempre solamente hacer las tareas necesarias para cumplir con el objetivo del Sprint y nada más. Diseñar por las dudas es un anti-patrón, lo que hacemos es refactorizar en base a los requisitos nuevos.
Seguir las siguientes prácticas generales:
- Mantener el cuerpo de los métodos corto. Evitar clases con muchos métodos.
- Usar
string.IsNullOrEmpty()y nomiString == "". - La formar correcta de comparar strings es la siguiente:
if (string.Compare(str1,str2,StringComparison.InvariantCultureIgnoreCase) == 0) // son iguales else // son distintos - Al concatenar strings usar string interpolation o
StringBuilder.var mensaje = "Hola " + usuario; //ERROR var mensake = $"Hola {usuario}"; //OK - La visibildad es importante. Si el método/propiedad puede ser privado que sea privado.
- Hacer estáticos los métodos que no accedan a ninguna propiedad de instancia.
- Siempre que se sobrecarga
GetHashCode()hay que sobrecargarEquals(). - Inicializar las auto-properties y las variables miembro con valores default cuando sea posible y no en el constructor.
public class Foo { public string Bar { get; set; } = "bar"; } - En lo posible, exponer las interfaces de colecciones más estríctas. Preferir
IEnumerable<string>aICollection<string>y esta última aList<string>. Pensá que el llamador puede modificar la colección sin que tu clase lo sepa. Eso a veces puede no ser lo mejor.
Microservicios
La forma deseada de diseñar las soluciones es usando el patrón de microservicios. La diferencia con un tipo de diseño monolítico o clásico principalmente reside en que en lugar de asociar una solución a una única pieza de software, la solución se compone de varias piezas independientes conectadas entre sí. Esto trae varios beneficios (aunque algunas contras, nada es infalible). No es tan sencillo pensar en microservicios para alguien que viene de otras estrategias y una discusión profunda del tema queda fuera del alcance de este documento. Lo mejor para iniciarse es consultar con los referentes técnicos de GLA y buscar ejemplos de soluciones así diseñadas que ya están en producción; por supuesto, tambien leer.
Platform
Platform es un chasis para la creación de microservicios en .Net y .Net Core utilizado por Andreani para la creación aplicaciones. Es de vital importancia que lo estudies si vas a programar en .NET, te va a sacar andando en seguida. Consultar la Wiki del proyecto o a cualquiera de los referentes técnicos.
Diseño de APIs
Cuando un servicio deba exportar APIs debe seguir el diseño especificado aquí si es una api privada, es decir, solo se accede desde la LAN; o aquí si es un api pública, es decir, se accede desde internet. Es conveniente que las apis cuenten con documentacion para que quienes la quieran usar puedan hacerlo fácil y rápida. La documentación deberá hacerse en formato OpenApi y debe ser accesible desde http://mihost.com/api/api-docs.
Integraciones
Introducción a la intregración por mensajería.
Toda comunicación entre sistemas es preferible hacerla de forma asincrónica.
Llamar a otras APIs. Cuestiones de dependencia.
Patrones de diseño para operaciones diferidas.
Patrones sharding.
Despliegues
Integración continua con Jenkins. Jenkins file.
Ambientes TEST, QA, PROD: